Do you get visual after-images when you stare at something for a while?
If so, how long do they last?
There are three theories of after images.
1. they happen in the retina because of the bleaching of photoreceptors
2. they happen in the retina and other areas because when the stimulus goes away, the removal of lateral inhibition causes rebound excitation
3. they happen in the visual cortex, and what happens in the retina is just simple adaptation.
By now we know that both retina and visual cortex are involved. This was determined by a careful analysis of the time course from psychophysics experiments, with the neural firing patterns of individual retinal ganglion cells.
 www.nature.com
www.nature.com
The retina is definitely involved, but the time course of retinal adaptation is either very fast or very slow, and the persistence of afterimages is somewhere in the middle.
 pmc.ncbi.nlm.nih.gov
pmc.ncbi.nlm.nih.gov
Here is my proposal from the standpoint of predictive coding:
The afterimages are perceptual. They can be perceived by closing the eyes (ie "in the absence of sensory input").
After images are persistent error signals. Predictive coding requires that the error signals hang around for a while, and they would behave in the same way as lateral inhibition (in other words, with rebound excitation).
This view also suggests a mechanism for hallucinations, as unmatched error signals.
The sensory visual system can be compared to a Kalman filter, or more specifically an information filter (which is a Kalman variant). Kalman filters are exactly like Bayesian estimators, they take the current state of the system (a priori), make a prediction of the next state (likelihood), and use it to calculate a difference (called error, based on an energy function or cost function), which is then used to update the filter parameters (a posteriori).
Kalman filters make the Markov assumption, which is "no memory", only the current state (and the input) is used to calculate the next state. They are a form of "hidden Markov process", which conveniently lets us add noise to any term (for analytic or generative purposes).
The Kalman filter has a time scale. Let us say the system state is sampled at time t1, and updated at time t2. Then you can look at the update as occurring at (t1+t2)/2, and r1 and t2 being equidistant from the origin. Let us imagine that these times now move farther away from each other, away from the origin in the direction of + and - infinity. Consider these scenarios:
1. You can stagger multiple Kalman filters.
2. You can increase or decrease the cycle time.
3. You can have all n Kalman filters connected together to pick up the similarities and differences in the model at each point in time. In this way you get a picture, of both the system states and the predictions.
In the information filter specifically, you can run multiple window spans through the same filter. Why this matters:
 en.wikipedia.org
en.wikipedia.org

This in turn affects downstream calculations like entropy.

So, when you're minimizing errors using the squared sum of residuals, this is the same as minimizing the cross entropy which is the same as minimizing the KL divergence (which is the distance between the actual and predicted distributions).
If so, how long do they last?
There are three theories of after images.
1. they happen in the retina because of the bleaching of photoreceptors
2. they happen in the retina and other areas because when the stimulus goes away, the removal of lateral inhibition causes rebound excitation
3. they happen in the visual cortex, and what happens in the retina is just simple adaptation.
By now we know that both retina and visual cortex are involved. This was determined by a careful analysis of the time course from psychophysics experiments, with the neural firing patterns of individual retinal ganglion cells.
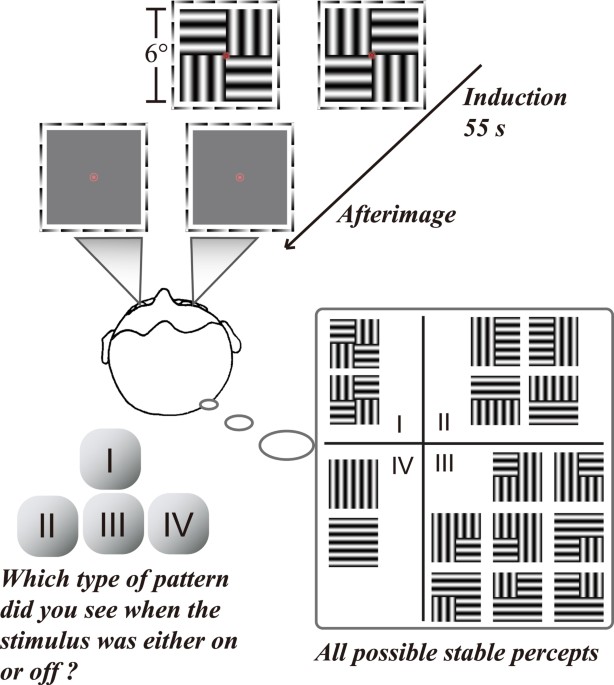
Cortical mechanisms for afterimage formation: evidence from interocular grouping - Scientific Reports
Whether the retinal process alone or retinal and cortical processes jointly determine afterimage (AI) formation has long been debated. Based on the retinal rebound responses, recent work proposes that afterimage signals are exclusively generated in the retina, although later modified by cortical...
www.nature.com
The retina is definitely involved, but the time course of retinal adaptation is either very fast or very slow, and the persistence of afterimages is somewhere in the middle.
Neural Locus Of Color Afterimages - PMC
After fixating on a colored pattern, observers see a similar pattern in complementary colors when the stimulus is removed. Afterimages were important in disproving the theory that visual rays emanate from the eye[1], in demonstrating inter-ocular ...
pmc.ncbi.nlm.nih.gov
Here is my proposal from the standpoint of predictive coding:
The afterimages are perceptual. They can be perceived by closing the eyes (ie "in the absence of sensory input").
After images are persistent error signals. Predictive coding requires that the error signals hang around for a while, and they would behave in the same way as lateral inhibition (in other words, with rebound excitation).
This view also suggests a mechanism for hallucinations, as unmatched error signals.
The sensory visual system can be compared to a Kalman filter, or more specifically an information filter (which is a Kalman variant). Kalman filters are exactly like Bayesian estimators, they take the current state of the system (a priori), make a prediction of the next state (likelihood), and use it to calculate a difference (called error, based on an energy function or cost function), which is then used to update the filter parameters (a posteriori).
Kalman filters make the Markov assumption, which is "no memory", only the current state (and the input) is used to calculate the next state. They are a form of "hidden Markov process", which conveniently lets us add noise to any term (for analytic or generative purposes).
The Kalman filter has a time scale. Let us say the system state is sampled at time t1, and updated at time t2. Then you can look at the update as occurring at (t1+t2)/2, and r1 and t2 being equidistant from the origin. Let us imagine that these times now move farther away from each other, away from the origin in the direction of + and - infinity. Consider these scenarios:
1. You can stagger multiple Kalman filters.
2. You can increase or decrease the cycle time.
3. You can have all n Kalman filters connected together to pick up the similarities and differences in the model at each point in time. In this way you get a picture, of both the system states and the predictions.
In the information filter specifically, you can run multiple window spans through the same filter. Why this matters:
Norm (mathematics) - Wikipedia
This in turn affects downstream calculations like entropy.
So, when you're minimizing errors using the squared sum of residuals, this is the same as minimizing the cross entropy which is the same as minimizing the KL divergence (which is the distance between the actual and predicted distributions).



