Okay, not sure if anyone understands what I'm talking about - but I'm going to coin a phrase.
At least I think I'm coining it, others have surely thought about it before but I can't find it in the literature.
The term is: "continuous recursion".
It has a specific meaning. It is not to be confused with "recursively continuous", which has a different meaning.
Here is a baseline definition:
An ordinary recursion is iterative. That means, it proceeds in discrete steps, which you can count. Even if the recursion is infinite, you can still count the steps (they're "countably infinite"). An example of an infinite recursion is a Cantor Dust. Each subdivision is a step. The steps can be asynchronous for different sub intervals, but they must always occur in order. An ordinary recursion therefore looks like this:
[x] = baseline
while(1)
... [x] = p([x])
The brackets signify that x can be an array, or a set. And, you (or the computer) can count how many times the process p is invoked. It may generate new elements, in which case they get added to the set. The process p proceeds element-wise on all members of x.
For example - in a Cantor Dust the baseline is x = the unit interval [0,1], and the process p says "cut each element into 3 parts". In the first iteration, the initial member of the set is destroyed, because it's cut into 3 parts. However each part is added back into the set, so after 1 iteration x has 3 members. If the recursion is synchronous x grows as 3^n, where n is the number of iterations. We could also do it asynchronously, by assigning available resources from a pool of k processors.
So now, consider this in differential form. We start with something that looks like this in the synchronous case:
x(t+1) = f(x(t))
where f = p (f is used here mainly to relate the discussion to the familiar math of differential equations). This looks very much like an ordinary delay equation. The problem here is we can NOT convert this into simple differential form right away. Ordinarily we would take the limit as dt => 0, but the issue is that x is discontinuous, even in the limit. The instant we apply p we have a step in x (one interval becomes 3).
"If" we have an asynchronous process, we could use a trick that was used by the early physicists, called "time coarse graining", to turn this APPROXIMATELY into an ordinary differential equation for purposes of analysis and thought experimentation, except for the discontinuity in x. We would end up with the world's simplest differential equation, x' = f(x).
But since we have a discontinuous x, we have no choice but to treat x as a random variable and use the Ito or Langevin calculus to make this look like a stochastic differential equation. To do that, we have to make the count of set elements explicit. And, we have to restrict our process p so that only one sub element is updated at a time. In practice then, this becomes a Monte Carlo algorithm where the random variable chooses which set member will be updated next. So this algorithm ends up looking exactly like a Hopfield neural network, except for the discontinuity in x (which in the Hopfield case could be considered as "the number of neurons").
With this knowledge we can now reformulate our algorithm as a genetic equation, where the chosen interval "dies" at each step, and 3 new intervals are "born" in its place. And note that we are NOT using a genetic method to solve the differential equation, we're doing the exact opposite. If we formulate our scenario in terms of population dynamics though, we can once again consider the action of k simultaneous processors, because more than one person can die and be born at the same time.
We still have a problem though. Population is discrete. You can have 20 people, but not 20.1 people. Our number of intervals (count of members in x) has to be discrete. Since we've already used n for the number of iterations and k for the number of processors, let's use m for the number of members in x.
To handle discrete components in stochastic differential equations we have to use a "master equation", which translates the evolution into a "transition matrix". Information on master equations can be found here:

en.wikipedia.org
These master equations are computationally difficult, much more so than ordinary differential equations - although some specific cases can be represented as coupled ODE's. For those who are interested, explanations can be found in these references, in increasing order of complexity:
Dive into the world of statistical mechanics with our in-depth guide to the Master Equation, exploring its principles, applications, and significance.

www.numberanalytics.com
The relevant part of the master equation is the "jump process", which describes our discontinuity.
But now that we understand the landscape, let's return to the point of this post, which is the concept of a
continuous recursion. The recursion we just looked at occurs in discrete time (or processing) steps, and the closest we could get to continuity was stipulating "one update at a time" and then summing over updates. So what then, is a "continuous" recursion? A clue comes from the physics of quantum entanglement. Here, we have quantum fluctuations in one body that act as "measurements" on another. Every time a fluctuation occurs some information is transferred from one body to the other, and the net result is a constant exchange of information. Which is, in fact, what keeps the two bodies entangled - their "correlation". Calculating the higher order moments in a quantum many-body scenario is a computational nightmare. However it can be done. Here is an example:
Our scenario is formally equivalent to "continuous measurement theory" in quantum mechanics.
Here are some tidbits on that:
We present a pedagogical treatment of the formalism of continuous quantum measurement. Our aim is to show the reader how the equations describing such measurements are derived and manipulated in a direct manner. We also give elementary background material for those new to measurement theory, and...

arxiv.org
We can define a continuous recursion as a process p in the "neighborhood"' of an element x.
This Collection highlights theoretical and experimental original research and commissioned commentary on topics in quantum many-body dynamics. The

www.nature.com
Especially check the highlighted section in this link:
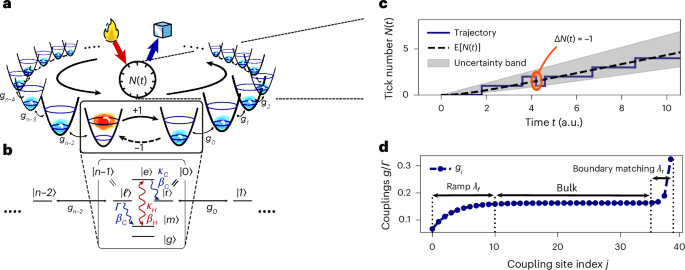
Can many-body systems be beneficial to designing quantum technologies? We address this question by examining quantum engines, where recent studies indicate potential benefits through the harnessing of many-body effects, such as divergences close to phase transitions. However, open questions...
www.nature.com
High precision quantum thermometer is the same as the high precision time definition in the OP.
One can also consider the "process" in terms of fields acting on the elements of x.
The higher order moments of the fluctuations for the thermodynamical systems in the presence of fields are investigated in the framework of a theoretical method. The metod uses a generalized statistical ensemble consonant with the adequate expression for the generalized internal energy. The...
arxiv.org
In the transform domain, we can perform topological recursion on spectra.
en.wikipedia.org
The principle is stated in a different way here:

www.math.uni-sb.de
... topological recursion is a recursive formula which computes a family of differential forms associated to a given spectral curve. It turns out these forms admit nice mathematical properties and compute interesting quantities in various field of mathematics. To mention some relations, the topological recursion computes
- Correlations functions in Random Matrix Theory,
- Hurwitz numbers in Enumerative Geometry.
- Gromov-Witten invariants and intersection numbers